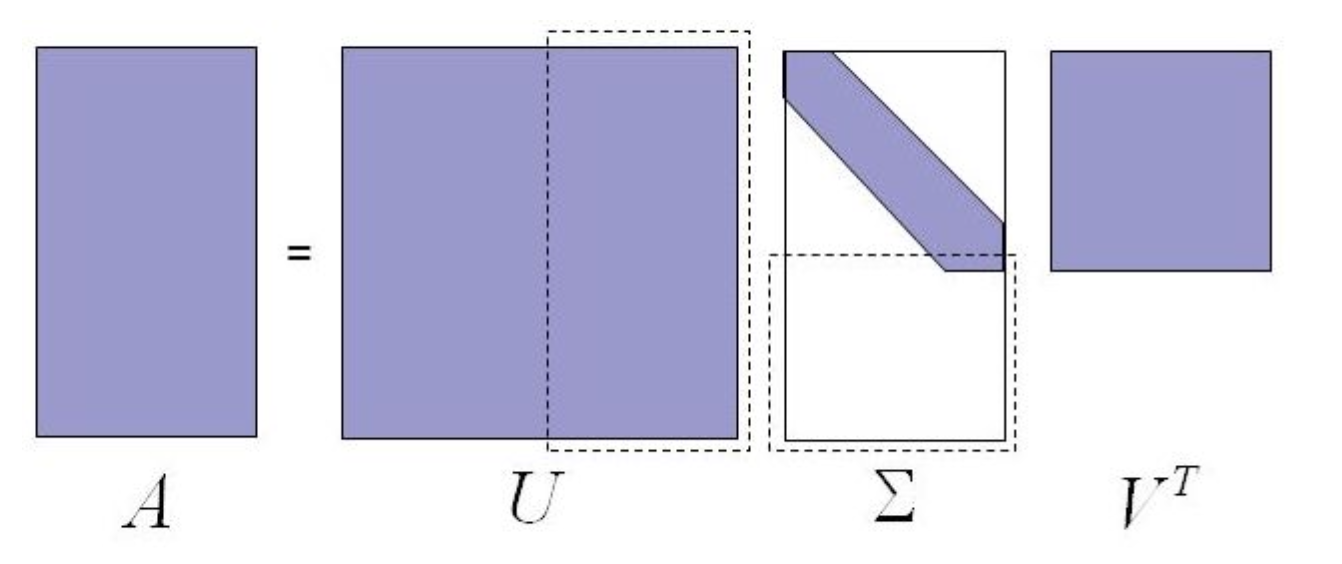
Singular Value Decomposition
SVD Theorem
For each matrix
- The set of singular values is unique
- Left/right singular vectors (columns or
and ) can have arbitrary sign
Computation Complexity
SVD is computable in
SVD and Frobenius norm
Let the SVD of
SVD and Spectral norm
Let the SVD of
Reduced SVD
One can often prune columns of